There has been a lot about diagrams recently – this is about the machine learning itself.
I don’t know about you, but one of the big problems I have is taking a guess at whether the latest ML approach is likely to work on the data I’ve got. Wouldn’t it be cool if we could test that, without having to implement the whole system?
A very brief summary of the paper
Take a CNN cat-photo classifier in Computer Vision. It works for photos from wikipidea, but will this approach work for my personal cat photos? We might expect that the features underlying would be similar (e.g. fundamental features of cats, such as the outline of their faces) but also some important aspects might not be (e.g. something about my own camera or photographing style might be different to what is found on wikipedia). This makes it hard to know if it will work. “Luckily”, in real life, we’ve given corporations so much access to our personal data that the classifier is already trained on real life photos :/.
The paper explores how the complexity of the data impacts the effectiveness of the approach, for the same task. What that means is that we can just look at the data itself (rather than train and run the algorithms) in order to take a guess at how good a particular approach might be. In business, this can save huge amounts of time an energy. The paper doesn’t get all the way to a full testing rig for this, instead laying theoretical groundwork and conducting a series of trials.
Exec summary
We might be able to guess the effectiveness of ML approaches based on the data alone.
Get in touch with fuza.co.uk if you’re interested in exploring this space further.
I’ve been running a “lean” business for 6 months now, and I’ve noticed that Lean Manufacturing principles applied to software development could lead to bad business. Let me explain:
Primarily, my concern centers around the lean manufacturing principle of waste reduction. The constant strive to reduce waste makes sense in an industrial production line, but does it make sense in a startup or exploratory environment?
An example
Let’s say there are 2 possible features you can work on. Feature 1 has a 90% chance of delivering £1 value, and Feature 2 has 10% chance of delivering £100 value.
Let’s say that the features take the same time to develop. From the maths,
Feature 1 “value” = 90% of £1 = £0.90
Feature 2 “value” = 10% of £100 = £10
And yet even with this understanding, because of the implicit risk and waste aversion of lean, we would say “there’s a 90% chance Feature 2 will be wasteful, whereas Feature 1 is sure to not be wasteful, therefore Feature 1 is a better idea”.
Good outcomes, but not as good as they could be
The waste reduction aspect of lean manufacturing gives us a local optimisation, much like gradient descent. Imagine a ball on a hill, which will roll downhill to find the bottom. This is ok, and it will find a bottom (of the valley), but maybe not the bottom (of the world, maybe the Mariana trench). In that sense it is locally good, but not globally optimal.
The way mathematicians sometimes get round this is by repeatedly randomly starting the ball in different places: think a large variety of lat-longs. Then you save those results and take the best one. That way you are more likely to have found a global optimum.
So I’m wondering about whether this kind of random restarting makes sense in a startup world too. I guess we do see it in things like Google’s acquisitions of startups, Project Loon, etc. Perhaps we/I should be doing more off-the-wall things.
Closing commentary
Perhaps it isn’t so odd that Lean Manufacturing has “reduce waste” as a principle… In a production line environment, reduction of waste is the same as increasing value.
Still, if the optimisation problem is “maximise value” this leads to different outcomes than “minimise waste”. I would argue we should, in almost every case, be focusing on maximising value instead.
As we’ve seen with following the rituals rather than the philosophy and mindset of agile, it is beneficial to actually think about what we’re doing rather than applying things without understanding.
Comments below please, I know this may be a bit controversial…
In a previous post, several months ago, we talked about Chaos and the Mandelbrot Set: an innovation brought about by the advent of computers.
In this post, we’ll talk about a present-day innovation that is promising similar levels of disruption: Open Data.
Open Data is data that is, well, open, in the sense that it is accessible and usable by anyone. More precisely, the Open Definition states:
A piece of data is open if anyone is free to use, reuse, and redistribute it – subject only, at most, to the requirement to attribute and/or share-alike
The point of this post is to share some of the cool resources I’ve found, so the reader can take a look for themselves. In a subsequent post, I’ll be sharing some of the insights I’ve found by looking at a small portion of this data. Others are doing lots of cool things too, especially visualisations such as those found on http://www.informationisbeautiful.net/ and https://www.reddit.com/r/dataisbeautiful/.
Sources
One of my go-to’s is data.gov.uk. This includes lots of government-level data, of varying quality. By quality, I mean usability and usefulness. For example, a lat-long might be useful for some things, a postcode or address for other things, or an administrative boundary for yet others. This means it can be very hard to “join” the data together, as the way they store something like “location” is many different ways. I often find myself using intermediate tables that map lat-long into postcodes etc., which takes time and effort (and lines of code).
Another nice meta-source of datasets is Reddit, especially the datasets subreddit. There is a huge variety of data there, and people happy to chat about it.
For sample datasets, I use the ones that come with R, listed here. The big advantage with these is they are neat and tidy, so they don’t have missing values etc and are nicely formatted. This makes them very easy to work with. These are ideal for trying out new techniques, and are often used in worked examples of methods which can be found online.
Similarly useful are the kaggle datasets, which cover loads of things from US election polls to video games sales. If you are inclined they have competitions which can help structure your exploration.
A particularly awesome thing if you’re into social data is the European Social Survey. This dataset is collected through a sampled survey across Europe, and is well established. It is conducted every 2 years, since 2002, and contains loads of cool stuff from TV watching habits to whether people voted. It is very wide (ie lots of different things) and reasonably long (around 170,000 respondents), so great fun to play with. They also have a quick analysis tool online so you can do some quick playing without downloading the dataset (it does require signing up by email for a free login).
Why is Open Data disruptive?
Thinking back to the start of the “information age”, the bottleneck was processing. Those with fast computers had the ability to do stuff noone else could do. Technology has made it possible for many people to get access to substantial processing power for very cheap.
Today the bottleneck is access to data. Google is making their business around mastering the world’s data. Facebook and twitter are able to exist precisely because they (in some sense) own data. By making data open, we start to be able to do really cool stuff, joining together seemingly different things and empowering anyone interested. Not only this, but in the public sector, open data means citizens can better hold government officials to account: no bad thing. There is a more polished sales pitch on why open data matters at the Open Data Institute (and they also do some cool stuff supporting Open Data businesses).
Some dodgy stuff
There are obviously concerns around sharing personal data. Deepmind, essentially a branch of Google at this point, has very suspect access to unanonymised patient data. Google also recently changed the rules, making internet browsing personally identifiable:
We may combine personal information from one service with information, including personal information, from other Google services – for example to make it easier to share things with people you know. Depending on your account settings, your activity on other sites and apps may be associated with your personal information in order to improve Google’s services and the ads delivered by Google.
We’ve got to watch out, and as ever be mindful about who and what we allow our data to be shared with. Sure, this usage of data makes life easier… but at what privacy cost.
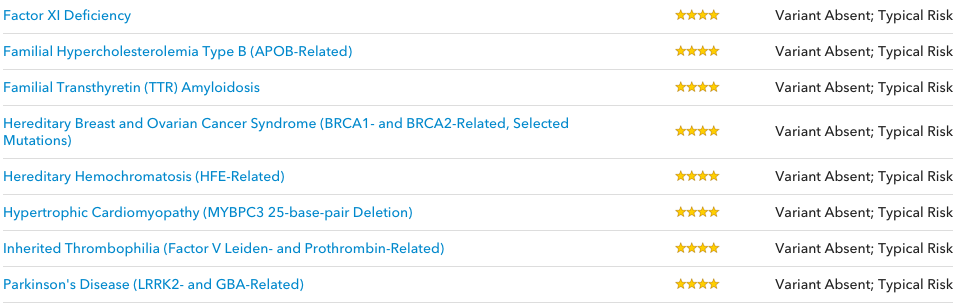
Data matters. A great example of a smart use of data is genetic sequencing. This involves 3 billion base pairs, although scientists only know what around 1% of these do. The arguably most important ones are to do with creating proteins. By looking at people with traits, diseases or ancestry, scientists have been able to pick out those sets of genes which seem to match with those attributes. For example, breast cancer risk is 5 times higher if you have a mutation in either of the tumour-suppressing BRCA1 and BRCA2 genes.
Due to science, there are now commercial providers of DNA sequencing available, such as 23andme. They market this as a way to discover more about your ancestry and any genetic health traits you might want to watch out for. To try this out, I bought a kit to see how they surfaced the data in an understandable way. The process itself is really easy, you just give them money and post a tube of your spit to them.
nice…
After a few weeks wait for them to process it, you can look at your results. Firstly, you have your actual genetic sequencing. This is perhaps really only of interest (or any use) to geneticists. As part of their service, 23andme pull out the “interesting” parts of the DNA which have been shown (through maths/biology) to correspond to particular traits or ancestry.
They separate this out into:
Health:
Genetic risks
Inherited conditions
Drug response
Traits (eg hair colour or lactose tolerance)
Ancestry:
Neanderthal composition
Global ancestry (together with a configurable level of “speculativeness”)
Family tree (to find relatives who have used the service too)
Part of what is smart about this service is that while it uses DNA as underlying data, it almost entirely hides this from the end user. Instead, they see the outcome for them. They have realised that people don’t care about a sequence like “agaaggttttagctcacctgacttaccgctggaatcgctgtttgatgacgt” but they do care about whether they have a higher risk of Alzheimer’s. Because some of these things are probabilistic, they also put a 1*-4* scale of “Confidence”: again this is easy to read at a glance. It isn’t very engaging, but it looks something like this:
Examples
Perhaps more visually interesting is the ancestry stuff. Apologies that my ancestry isn’t very exciting:
Ancestry, set to “standard” speculation levels (75% confidence)
I hope this has been interesting. Commercial DNA sequencing is a real success story not just for biochemistry and genetics, but also for the industrialisation of these processes and the mathematics and software that makes it possible. The thing that is especially cool, according to me at least, is the ability to make something as complex as genetics accessible, understandable and useful.
The average number of customers in a queuing system = ( the rate at which customers enter the system ) x (the average time spent in the system)
Typically this might be applied to things like shoppers in a supermarket, but here we will focus on the application to software development. In a software development world, we often write it the same statement with different words, thinking about tasks:
Average Work in Progress = Average Throughput x Average Leadtime
Little’s law is beautifully general. It is “not influenced by the arrival process distribution, the service distribution, the service order, or practically anything else”[1]. This almost makes it self-evident, and since it is a mathematical theorem perhaps this is correct, since it is true in and of itself. Despite being so simple to describe, the simplest generalised proof that I have been able to find (and which we will not tackle here) is however trickier, since a solid grasp on limits and infinitesimals is required. Instead, we will consider a restricted case, suitable for most practical and management purposes, which is the same equation, with the condition that every task starts and finishes within the same finite time window. The mathematical way of saying this is that the system is empty at time t = 0 and time t = T, where 0<T<∞. A diagram to show this system might look something like this:
Tasks all starting and finishing between t=0 and t=T
Proof
For our proof, we start with some definitions
n(t) = the number of items in the system at time t
N = the number of items that arrive between t = 0 and t = T
λ = the average arrival rate of items between t = 0 and t = T. The arrival rate is equal to the departure rate (sometimes called throughput), since the system is empty at the beginning and the end.
L = the average number of items in the system between t = 0 and t = T. This is sometimes called “average Work in Progress (WIP)”
W = the average time items spend in the system between t = 0 and t = T. This is called W as a shorthand for wait time, but in software development we might call this leadtime
A = area under n(t) between t = 0 and t =T. This is the sum of all the time every item has spent queuing.
Using this notation, Little’s law becomes
L = λ x W
which we will prove now. The following equations can be assembled from these definitions. We will need to use these to assemble Little’s Law.
L = A/T(average number of items in the system = sum of time spent / total time)
λ = N/T(average arrival rate = total number of items / total time, since every item leaves before t=T)
W = A/N(average time in system = sum of all time spent / number of items)
We can now use these three equations to prove Little’s Law:
L = A/Tfrom (1)
= (A/T)x(N/N) since N/N = 1
= (N/T)x(A/N)by rearranging fractions
= λ x Wfrom (2) and (3)
This is what we wanted, so the proof is complete.
What does this mean?
A trick to getting good outcomes from Little’s Law is understanding which system we want to understand.
If we consider our queuing system to be our software development team, our system is requirements coming in, then being worked on and finished. In this case, W is the development time, and each item is a feature or bug fix, say.
To have a quicker time to market, and to be able to respond to change more quickly, we would love for our so-called “cycle time” W to be lower. If the number of new features coming into our system is the same, then we can achieve that by lowering L, the average work in progress. This is part of why Kanban advocates “limiting work in progress”.
Alternatively, we can consider our queuing system to be the whole software requirement generation, delivery, testing and deployment cycle. In this case, we might have W being the time taken between a customer needing a software feature to it being used by them. By measuring this, we get a true picture of time to market (our new W, which is true measure of “lead time”), and we with some additional measurements we would be able to discover the true cost of the time spent delivering the feature (since our new A is means total time invested).
Outside of the development side of software, we can apply Little’s Law to support tickets. We can, for example, state how long a customer will on average have to wait for their query to be closed, by looking at the arrival rate of tickets and the number of items in the system. If there are on average 10 items in the queue and items arrive at 5 per hour, the average wait time will be 2 hours, since the rearrangement of Little’s Law to L/λ= W gives us 10 / 5 = 2.
I hope that was interesting, if you would like me to explain the proof in the general case, let me know in the comments. I think it would be about 10 pages for me to explain, so in the spirit of lean I will only do this if there is a demand for it.
Orley Ashenfelter, an economist at Princeton, wanted to guess the prices that different vintages of Bordeaux wine would have. This prediction would be most useful at the time of picking, so that investors can buy the young wine and allow it to come of age. In his own words:
The goal in this paper is to study how the price of mature wines may be predicted from data available when the grapes are picked, and then to explore the effect that this has on the initial and final prices of the wines.
For those of you not so au-fait with wine, prices vary a lot. At auction in 1991, a dozen bottles from Lafite vineyard were bought for:
$649 for a 1964 vintage
$190 for a 1965 vintage
$1274 for a 1966 vintage
Wines from the same location can vary by a factor of 10 between different years. Before Ashenfelter’s paper, people predicted wine quality by experts, who tasted the wine and then guessed how good it would be in future. Ashenfelter’s great achievement was to bring some simple science to this otherwise untapped field (no pun intended).
He started by using the things that were “common knowledge”: in particular that weather affects quality and thus selling price. He checked this by looking at the historical data:
In general, high quality vintages for Bordeaux wines correspond to the years in which August and September are dry, the growing season is warm, and the previous winter has been wet.
Ashenfelter showed that 80% of price variation could be down to weather, and the remaining 20% down to age. With the given inputs, the model he built was:
log(Price) = Constant + 0.238 x Age + 0.616 x Average growing season temperature (April-September) -0.00386 x August rainfall + 0.001173 x Prior rainfall (October-March)
As it turned out, this simple model was better at guessing quality than the “wine expert”: a success for science against pure intuition. The smart part of his approach was getting insight in to the things people felt mattered (weather) and checking that wisdom. Here, he showed that yes it is quite appropriate to use weather and age to model wine prices.
Through the age variable, it also gives an average 2-3% annual return on investment [1] (note this is pre-2008 so is unlikely to behave like this today[2]).
Should I buy wine? Quite possibly, as long as I don’t drink it all.
Today I want to share some thoughts around data-driven decisions. Rather than present some evangelical-sounding argument, I think it might help if I speak from my personal experience:
I care about data because it is the only way I know if I’m getting better.
It also helps me to think about what truly matters.
Seriously, I apply this to everything: from my work, to my workouts, to my gardening, to my…
Enough of that. Let’s take a real example: let’s say our goal is
“Make the company culture better”
The first obvious question is what does “better” mean? This is always worth a proper discussion. For our purposes now, let’s say we’ve agreed for our purposes it means that people enjoy being at work, and are productive.
So how would we know if we were changing that? That’s when it gets difficult, and very important, to measure: since then we can see what things (experiments) we do that impact this.
On the “people enjoying being at work” topic, we might look at some quantitative measures from People data such as “rate at which people leave the company” or “hiring ability”, together with some softer, qualitative, conversation-based data. We might even want to construct things, like a culture survey or exit interviews, to understand some specific aspects of what matters to us.
Then in terms of “productivity” (or some measure of value delivered), we might want to look at the customer benefit delivered each week, in £. This might be too hard (indeed I’m not sure anyone has cracked it [1]), so we’re looking at throughput (a count of stories done in a time interval) instead as a proxy-measure. If you have any ideas of how we could do that better I’d be really keen to hear them!
Following scientific method:
First, we want a baseline: to capture what the current status of these things is.
Then, we want to conduct smart, hypothesis-driven experiments, so we can see if these genuinely do impact things: being sure to take repeatable measures.
Unfortunately for our example, this interactive human behaviour is almost the definition of a Complex Adaptive System [2], so it won’t be easy to show causation – we’d need to do some Principle Component Analysis [3] (or similar) and that would require “long” and ideally also “wide” data, together with experiments and consciously-held-out subsets. In a business environment, this is hardly pragmatic.
We can though at least show that something important has changed, even if we can’t easily prove why it changed.
By gathering data that matters, you too can be data-driven! Experiment with this on something simple to start with, and see whether it works for you. It might be what time of day to commute to work, your own wellbeing, or the quality of your code. Let us know in the comments below what you try and how it goes!
One of the things I’m trying to optimise for is my happiness. Hopefully it doesn’t come as a huge surprise that this is a pretty complex thing to do. In my time as an Agile Coach, I’ve read a lot of literature of varying quality on this, and indeed hopefully have helped others to use this to find increased happiness for themselves.
From the studies supporting “Thinking fast and slow” it is clear that present happiness and “remembering happiness” are two very different things, both of which would need to be considered. [1]
A happy (in the present) panda
Through my reading of several studies, there is one key thing that I want to call out in this post: social connectedness. It turns out that social connectedness is a better predictor of happiness than any other variable (such as money or education).[2]
As someone going from full-time employment (with a built-in 5-day-a-week social) to self-employment, I was worried that I’d lose a lot of the social connection I had in my life.
To combat this, I agreed to spend 2 days a week in an office coaching teams. I also joined a few local clubs, and committed to myself that I’d go to some interesting meetups.
I’ve also been measuring my happiness day by day, and reflecting on it, in order to cover both “types” of happiness. I draw smileys on my calendar each morning, and do a monthly check on how I feel the last month was.
With thanks to Tung Chun Food Manufacturing Ltd.
I know this isn’t very advanced, or even scientific. By using this basic data, I’m trying to understand just a bit more about how I feel, and see whether changes I make (such as joining a club, or doing more running) make a measurable difference to my happiness. Also, through the mere fact that the data exists, I ensure I focus on it more, which is what I want anyway! [3]
Here is my short, simple step-by-step guide for smart collection of data.
Step 1) Determine what matters, ideally in accordance with a Company or Product vision
Step 2) Come up with as many different ways of measuring aspects that matter or impact what matters
Step 3) Collect data! Ideally setting up easily repeatable ways of this, and automated wherever possible
Step 4) Form hypotheses: how do you believe certain measures affect your vision? What do you expect the data to tell you?
Step 5) Collect more data
Step 6) Test your hypotheses
Step 7) Collect even more data. Quite simply, the more data the better.
Bletchley Park: the more data the better
Let’s look at an example. Suppose a government manager wishes to improve the innovation of her employees.
Step 1) Target: what matters here is “innovation” – which we define more precisely in…
Step 2) Measurement: Some of the ways in which innovation can be measured are volume of ideas, number of staff submitting ideas, percentage of staff submitting ideas, value delivered, employee perception of innovation produced, manager perception, and customer perception (in this case the public would be the customer), etc.
Step 3) Collection: This involves ensuring that things are centrally recorded and surveys are done to create a baseline.
Step 4) Hypothesis: It is suggested that an innovation rewards’ ceremony would help to improve the morale. Note that it is important that the hypothesis is formed after the first data collection, as we want to be able to dig deeper into anything interesting we find. This means that often we need to collect more detailed data more specifically targeted towards proving or disproving our hypothesis.
Step 5) Collection: A more accurate, probably quantative, measure of morale is added to the existing survey.
Step 6) Action: An innovation rewards’ ceremony is run.
Step 7) Collection: The survey is conducted again – morale is measured as having improved. Success! Note that the other measures (e.g. the volume of ideas produced) are now also being consistently measured and can be easily tracked throughout future experiments.
After running through these steps we can ask ourselves the following questions.
What do we now know?
Key measures, and how they are changing with time
Whether the key measures remain the same, or if other aspects should be considered.
What can we not imply?
“Correlation does not imply causation”: just because a trend becomes apparent this does not mean that one workplace modification is the main contributor to a measured difference. For example, if morale improves during the summer months this may have been due to nicer, warmer weather rather than any particular managerial decisions.
We cannot assume that any trends apply in similar cases elsewhere: our sample is too small and too specific. Luckily, a full research paper is not the goal here!
As some of you may have noticed, this is very similar to the Six Sigma methodology of “Define, Measure, Analyse, Improve, Control”. It also mirrors the “Plan, Do, Check, Act” process found in many management handbooks.
The detail of the steps you yourself follow is not particularly important here, all I am really suggesting is to:
Ensure you are working on what really matters.
Add wider data collection before directing all your attention to one particular area. This way you will have a richer understanding of the problems and opportunities.