In the past week, I’ve been to some excellent talks. The first was on Biomarkers at the Manchester Literary and Philosophical Society, and the second was Misinformation in Climate Change at Manchester Statistical Society. And both of these followed the IMA’s Early Career Mathematicians conference at Warwick, which had some excellent chat and food for thought around Big Data and effective teaching in particular.
Whilst I could share my learnings about biomarkers for personalised medicine, which makes a lot of sense and I do believe it will help the world, instead I will focus on climate change. It was aimed at a more advanced audience and had some excellent content, thanks Stephan Lewandowski!
There are a few key messages I’d like to share.
Climate is different to weather
This is worth being clear on: climate is weather over a relatively long period of time. Weather stations very near to one another can have very different (temperature) readings over time. Rather than looking at the absolute value, if you instead look at the changes in temperature you will be able to find correlations. It is these that give us graphs such as:
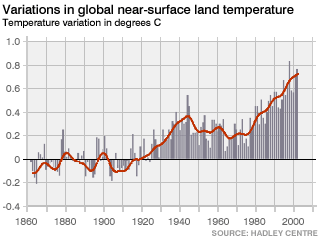
Misinformation
Given any time series of climate, it is possible to find local places where the absolute temperate trend goes down, particularly if you can pick the time window.
Interestingly, Stephan’s research has showed that belief in other conspiracy theories, such as that the FBI was responsible for the assassination of Martin Luther King, Jr., was associated with being more likely to endorse climate change denial. Presumably(?) this effect is related to Confirmation Bias. If you’re interested in learning more, take a look at the Debunking Handbook.
Prediction is different to projection
According to Stephan, most climate change models are projections. That is, they use the historical data to project forward what is likely to happen. There are also some climate change models which are predictions, in that they are physics models which take the latest physical inputs and use them to predict future climate. These are often much more complex…
Climate change is hard to forecast
I hadn’t appreciated also how difficult to forecast El Niño is. El Niño is warming of the eastern tropical Pacific Ocean, the opposite (cooling) effect being called La Niña. Reliable estimates for El Nino are available around 6 months away, which given the huge changes that happen as a result I find astonishing. The immediate consequences are pretty severe:
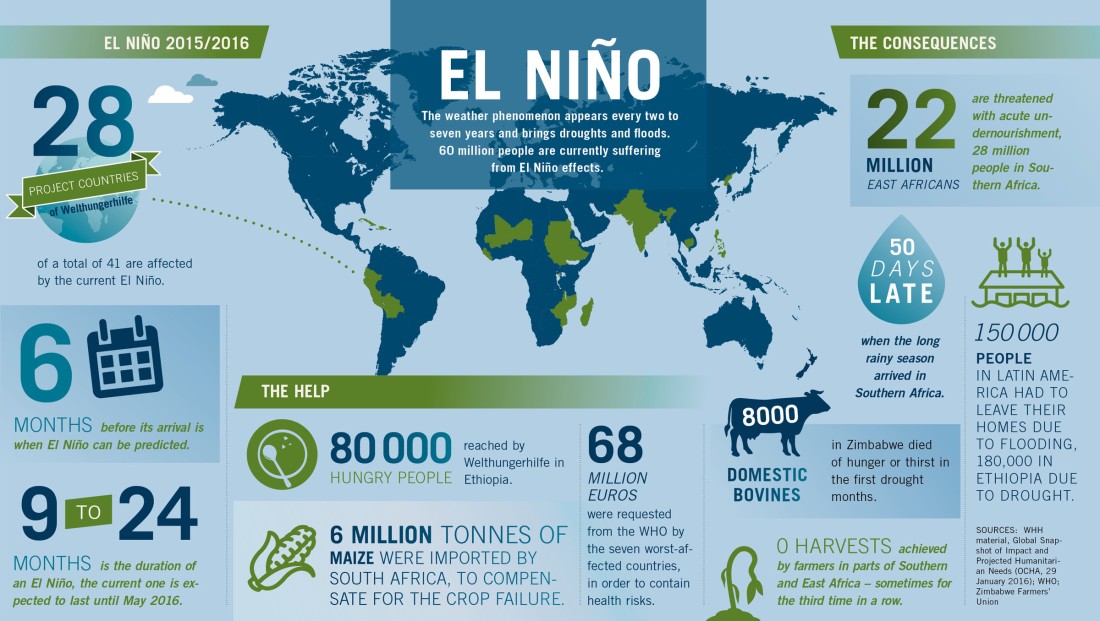
As you can see from the above infographic, it turns out that El Niño massively influences global temperatures. Scientists are trying to work out if there is a link between this and climate change (eg in Nature). Given how challenging this one section of global climate is, it is no wonder that global climate change is extremely difficult to forecast. Understanding this seems key to understanding how the climate is changing.
The future
In any case, our climate matters. In as little as 30 years (2047), we could be experiencing climatically extreme weather. Unfortunately since CO2 takes a relatively long time to be removed from the atmosphere, even if we stopping emitting CO2 today we would still have these extreme events by 2069. Basically, I think we need new tech.


 is bounded. These z are complex numbers, which we’ll ignore for now. It is much easier to understand if we look at some examples:
is bounded. These z are complex numbers, which we’ll ignore for now. It is much easier to understand if we look at some examples:
